
Hitachi Vantara升级Skylaking服务器加入Optane缓存和GPU
Hitachi Vantara利用Skylake处理器升级了更多服务器,并增加支持Optane SSD缓存和Nvidia GPU。
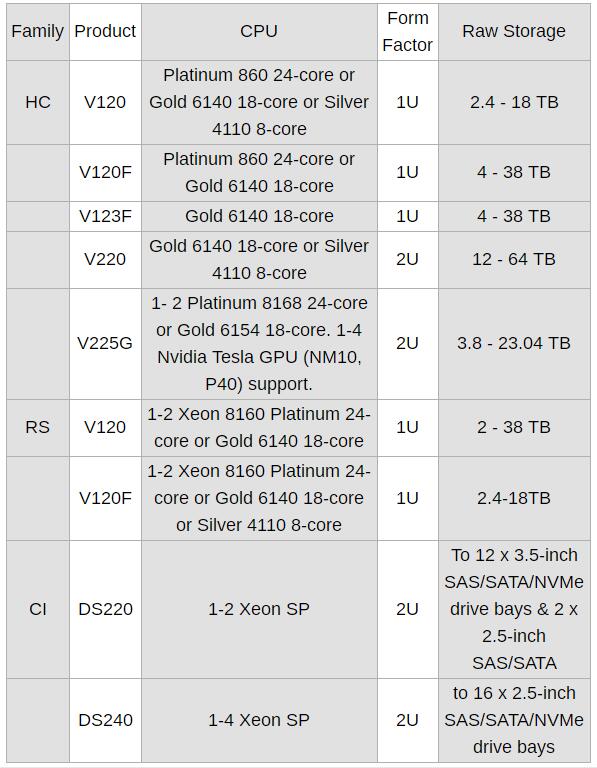
Vantara有基础的统一计算平台(UCP)服务器、DS(nnn)型号,然后针对V(nnn)型号的VMware环境进行了优化。这些V(nnn)型号可用于超融合(HC)和机架式(RS)产品系列:

这些都是1U或2U机箱中的单节点系统。“F”后缀代表是全闪存服务器;其他则是闪存/磁盘的混合式设计。“G”后缀代表是利用Nvidia GPU加速的系统。DS220和DS240服务器则用于融合基础设施(CI)产品组合中:
V123F(DS120基础)采用375GB Optane 3D XPoint P4800X缓存驱动器。
这是Hitachi V的第二波Skylake服务器。去年8月日立发布了第一台Skylake RS和HC服务器,其中有4款V(nnn)型号:
- V120F全闪存 - 1U单节点
- V210混合 - 2U 1节点
- V210F全闪存 - 2U单节点
- V240F全闪存 - 2U 4节点
最新公告中使用的产品名称是V120F。
这款超融合系统使用vSan和RS系统支持VMware Cloud Foundation。Hitachi Vantara的CI系统包括最新的VSP存储、UCP Advisor、DS220和DS240服务器。
以前Hitachi Vantara V拥有一个CB600刀片服务器产品线,6U机箱中有8个刀片服务器。最新公告中没有提及Skylake刀片服务器或磁带服务器。
现有的UCP Advisor管理和编排软件支持这些新的服务器。
其特点是针对SAP HANA进行了配置,数据湖中有一个运行在RS服务器上的MongoDB群集。有针对Cloudera和MongoDB的参考架构,带有针对Cloudera Enterprise Data Hub和MongoDB Enterprise的预测试、预验证基础架构,此外还集成了Pentaho Data [分析]。
这些新的UCP服务器、系统和应用产品预计将于8月份上市。
根据IDC的说法,Hitachi Vantara有了这些新型号,尤其是Optane缓存和Nvidia GPU的新型号,它将收回一些失地。
来源:The Register
好文章,需要你的鼓励


如何根据工作需求选择合适的戴尔AI笔记本电脑
购买笔记本电脑时,用户现在需要了解Copilot+ PC、NPU和本地AI处理等新概念。搭载专用神经处理单元(NPU)的Copilot+ PC能提供至少40 TOPS的AI算力,支持实时字幕翻译、视频通话优化、AI图像编辑等功能,同时提升续航表现。戴尔最新产品线涵盖多种选择:Dell 14 Plus适合学生和通勤族,Dell 16 Plus适合多任务办公用户,XPS 14面向轻度创作者,XPS 16则以31小时超长续航和3.6磅轻薄机身成为内容创作者的旗舰之选。

训练完AI助手,竟然还藏着一把免费的“评分钥匙“?威斯康星大学麦迪逊分校揭秘强化学习的隐藏宝藏
强化学习训练AI时悄悄留下的"进展优势"信号,可作为免费的步骤级评分器,无需额外训练,在多个智能体任务上超越专用奖励模型。

微软量子计算突破遭学界质疑,Majorana芯片成果存疑
圣安德鲁斯大学博士Henry Legg在《自然》杂志发表同行评审论文,对微软拓扑间隙协议(TGP)框架提出质疑,认为该框架在推断Majorana粒子量子态存在方面存在缺陷,且实验数据分析结论可能有误。微软此前宣称将于2029年实现可扩展量子计算机,并推出Majorana 2芯片。对此,微软坚持立场,表示已发表正式反驳并获《自然》收录,对研发路线图充满信心。

阿里巴巴团队打造的“AI图像秘书“:当AI学会主动“补课“,图片生成终于能读懂你的弦外之音
阿里团队推出Qwen-Image-Agent,通过规划、推理、搜索、记忆和反馈五大模块,主动填补用户需求与AI生成所需信息之间的"情境鸿沟",并配套发布IA-Bench评测基准。

