
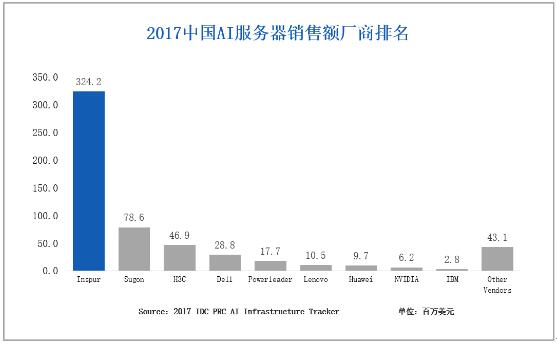
IDC:2017年中国AI基础架构市场增速235%,浪潮占比57%居第一
日前IDC公布2017年中国AI基础架构市场调查报告,报告显示,2017年中国AI服务器整体销售额5.68亿美元,出货量27863台;从竞争格局层面,浪潮份额明显领先其他厂商,居市场第一,出货量达到14,674台,销售额达3.24亿美元,占比分别为52.7%和57%,超过其他厂商份额的总和。
AI仍是台风中心 未来五年GPU服务器占比16.6%
原引IDC报告,AI"仍然处于台风中心",2017年AI市场的整体投入达到8.65亿美元,同比增长240%,未来5年复合增长率将超过50%,AI市场包括了硬件、软件和服务三大细分领域。
硬件系统部署对于AI发展至关重要,也是AI市场主要构成,2017年AI硬件销售额同比增长235%,在AI整体市场占比72.4%,预计到2022年市场容量将达到37.7亿美元,其中GPU服务器采购将达34亿美元,占整体x86服务器市场的16.6%。
AI进入新纪元 互联网是主要推动力
互联网运营商仍然是AI发展的力量主体,采购额为4.07亿美元,占整体市场的71.7%。
2017年是AI发展转折性的一年。此前腾讯、阿里巴巴、百度投资构建的专业AI基础架构,以支持行为分析、搜索、广告点击预测等运营商内部业务系统为主,到2017年,几乎所有互联网运营商都开始加大AI业务投资,加快AI基础设施建设,一些大型CSP开始对外提供AIaaS云服务。
IDC数据显示,浪潮市场优势核心来自于互联网行业,市占率达68%。百度、阿里巴巴、腾讯TOP级运营商90%以上AI服务器来自浪潮,今日头条、科大讯飞、网易、平安等Tier2、Tier3互联网运营商和行业用户也在大批量采购浪潮的各类AI基础架构的系统方案及产品。
4GPU和8GPU出货占比提高
AI基础架构在实际应用驱动下快速更迭。以GPU服务器为例,由于GPU跨节点通信瓶颈问题,服务器支持的GPU数量越来越大。根据IDC报告,2017年4GPU和8GPU服务器出货比例提高,销售额占比分别为36.9%和25.8%。
浪潮是目前GPU服务器产品线最齐全的厂商之一,2017年相继发布了SR-AI 整机柜服务器、AGX-2超算服务器、GX4 AI加速扩展Box等AI新品。SR-AI是全球首个采用PCIe Fabric互联架构设计的AI方案,可实现支持16个GPU的超大扩展性节点,该方案最大支持64块GPU,并且很好的解决了供电与散热问题,这款产品符合天蝎2.5标准,适合于超大规模云数据中心部署。AGX-2是全球首款在2U空间内高速互联集成8颗最高性能GPU加速器的服务器,是目前性能密度最高的AI基础架构方案,适合于各种数据中心环境。
传统行业不可忽视
虽然当前AI发展和应用主体力量是互联网运营商,但是传统行业将是AI未来更大的发展空间,尤其是金融、电信、零售、医疗健康等行业的AI应用将会更快,制约AI在传统行业应用的主要问题是用户技术能力缺乏,尤其是AI系统方案的部署运维。
在不断巩固互联网优势的同时,浪潮构建了完整的AI系统平台,即计算平台、管理套件、框架优化、应用加速四个层次,包含GPU、FPGA等AI服务器系列、深度学习训练集群管理软件AIStation、AI性能调优工具Teye以及集群版开源深度学习框架Caffe-MPI等完整解决方案。
浪潮集团副总裁彭震表示,浪潮正在构建深入行业场景的AI产业生态,和伙伴一起为用户提供端到端的AI整体方案,推进AI更广泛的商业化场景。
新时代塑造新格局
彭震表示,数据中心层面的云计算变革和应用层面的AI变革将推动基础架构产业的创新与重构,浪潮业绩的高速增长得益四大动力,创新的JDM业务模式、智能工厂投产、开放计算推进及AI市场的提前布局,深耕AI仍将是2018年浪潮的核心策略之一。
在刚刚结束的IPF18浪潮云数据中心合作伙伴大会上,浪潮发布全新AI品牌--TensorServer,同时启动T计划。浪潮希望抓住新时代下的两大发展机遇,在5年内成为全球最大的计算方案供应商。
好文章,需要你的鼓励


遭黑客入侵的Klue称犯罪分子正在删除窃取的客户数据,但新的黑客组织接连发出威胁
市场研究公司Klue本月初遭黑客入侵,大量客户数据被窃。Klue表示正与黑客组织Icarus沟通,并相信对方正在删除所盗数据。受影响客户包括Gong、LastPass、HackerOne等多家知名企业。然而事态趋于复杂——另一黑客团伙声称从Icarus处获取了Klue客户数据,并向客户发出勒索威胁。Klue提醒客户勿向第二方支付赎金,并建议索取数据样本以核实其真实性。

机械手臂终于学会“看深度“了——KAIST联合POSTECH研究团队让机器人规划与执行真正说同一种语言
KAIST等机构提出3D HAMSTER,通过为视觉语言模型加入深度编码器和几何重建损失,让机器人规划器直接输出三维轨迹,解决了分层机器人系统中规划与执行的维度不匹配问题,显著提升了操作鲁棒性。

苹果起诉OpenAI窃密:前员工利用零日漏洞下载机密文件
苹果公司对OpenAI提起诉讼,指控其窃取商业机密。据披露,前苹果系统电气工程师刘畅(Chang Liu)在离职加入OpenAI后,利用一个此前未知的身份验证零日漏洞,持续数周从苹果内部网络存储中下载大量机密文件,内容涵盖未发布产品信息、工程演示文稿及技术规格等。苹果已修复该漏洞并终止相关访问权限。此案已提交加州北区联邦法院,并要求陪审团审判。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。
2018
05/17
11:10
分享
点赞

QumulusAI直接上市:加速面向企业AI的新型云服务
微软Exchange Server本地版使用门槛再度提高
新AI路线图能否约束科技巨头?
AI赋能医疗研究:如何在速度与质量间找到平衡
Applied Computing获2000万美元融资,为油气行业打造全厂AI基础模型
麻省理工学院新系统GIFT:让AI将2D设计高效转化为3D模型
Canvas母公司Instructure与两度入侵其系统的黑客达成协议
Grafana Labs遭黑客入侵后拒绝支付赎金
纽约公共医疗系统遭黑客入侵,逾180万人数据及指纹信息被窃
GitHub遭黑客入侵,约3800个内部代码仓库数据被盗
7-Eleven数据泄露事件波及逾18.5万人个人信息
黑客组织ShinyHunters声称入侵逾百家机构Oracle PeopleSoft服务器
