
2018年,企业级存储厂商如何提升其营收? 原创
最近看数据存储领等方面全球营收以及发展报告。根据相关报告总结出一些建议,如果2018年存储领域的相关厂商能够在这几个领域发力,就可以很大程度上提升其年度营收来获得品牌和服务价值等方面的增值。
首先,在企业级领域围绕闪存和企业级硬盘发增加企业应收展将
全球来看,在2017年闪存SSD的收入为249亿美元磁盘为240,亿美元。也就是说在2017年,客户在SSD产品层面的支出首次超过磁盘。但是我们也看到了从出货总容量来看,磁盘存储出货容量仍达到闪存的十倍以上。
根据最新的报告显示,2017年全球企业级SSD出货存储容量总计达7.18 EB,较上年同期的5.57 EB增长29%。

而在企业级硬盘领域,随着视频监控领域、公有云领域以及对象存储领域对手海量数据增长的需求,希捷、西数以及东芝还在积极推动磁盘技术的发展。大容量、低成本、低能耗的企业级磁盘还将在未来几年在数据中心领域占有很大的份额。
2018年存储厂商可以分别闪存和硬盘方面继续双重出击。
再闪存方面基于最新的闪存技术在积极推动。西部数据公司最近已经确认了基于其专有控制器架构的新一代CSSD PCIe产品; 首款面向移动设备的UFS产品; 外加96层BiCS4 NAND技术。英特尔力推存储级内存,Storage Class Memory,简称SCM概念。这是介于DRAM和NVME之间的一个非易失性存储。
这其中华为认为这将导致SCM(存储级内存,Storage Class Memory)1.0时代的到来,通过在SCM介质、NVMe和NVMeoF的速度之间的平衡,构建新一代全闪存系统。
在硬盘方面基于海量存储技术推动,希捷科技日前发布12TB企业级海量盘,该盘兼具大容量及业界最低能耗和最轻重量,满足个人和公共云数据中心日益增长的存储需求。东芝也发布了14TB氦气海量硬盘。所以存储厂商要在2018年获得增长,需要在这两方面进军,一方面是基于闪存的全闪存阵列进军关键系统业务增长。一方面基于海量硬盘的存储系统,包括在视频监控领域、公有云、对象存储等领域的海量数据存储的需求。
这里我们看到,在闪存领域, NetApp积极布局,公司公布的最新财报当中,全闪存全年总营收为15.2亿美元,较上年全年的14亿美元增长8%。华为2017前三季度厂商全闪存存储 全球收入增速第一,高达200%以上的增长。
在大容量磁盘领域包括百度、腾讯、阿里等公有云服务商以及浪潮、曙光等积极与各个磁盘生产上在企业级存储、硬盘技术以及闪存解决方案等领域开展深入合作,并建立联合实验室,促进中国云计算、大数据的持续健康发展。
其次,围绕超融合系统发展,将成为2018年重要的营收增长点
在2018年,全球主要存储厂商将重点关注在超融合领域。Gartner报告显示,在2017年,全球集成系统收入预计在2018年达到123亿美元,比2017年的102亿美元增长18.4%。
而这主要增长是超融合系统。超融合集成系统2017年营收28亿美元,预计2018年营收44亿美元,增幅为55%,这个增长相信各大存储厂商非常眼红,也可以看到各大存储厂商将在2018年继续积极投入到超融合系统中来。
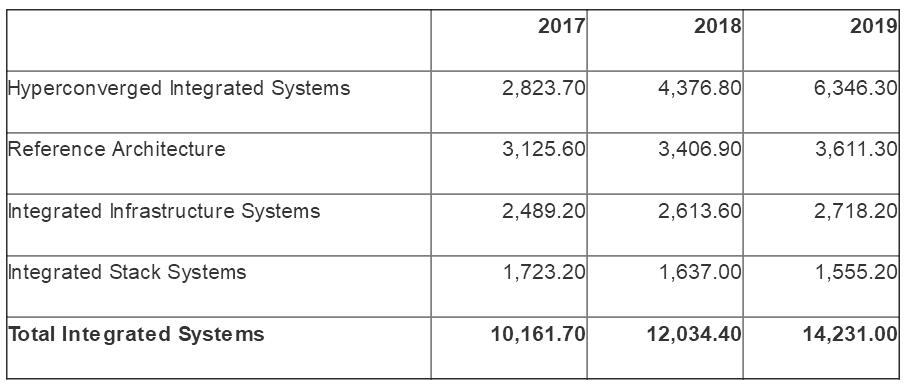
资料来源:Gartner(2018年3月)
在超融合市场方面包括,Dell EMC存储业务全年营收达到153亿美元,其中超融合产品组合实现三位数需求增长。超融合领域领导者Nutanix在2018年已经收购了两个初创企业,包括公有云计费系统和分布式云空间中发现、映射和管理微服务。积极推动超融合系统不断扩展到更多领域。
最后,基于云的数据管理和保护将成为存储领域的营收增长点
随着企业业务的增加和数据的增长,数据的管理和保护越来越重要,将拉动存储营收的大幅度增长。从业务上看基于人工智能、物联网、机器学习等技术的应用产生的数据价值越来越大,从数据量来看,各种交易数据、视频、音频、文档、邮件及移动数据增长等,因此数据保护,从本地存储再到云上数据,数据的保护、备份、恢复对于企业的重要性愈发凸显。
可以预见在数据备份和保护领域,如果围绕云和虚拟化环境开发数据保护技术,那么其将具有满足企业业务需求的核心竞争力。
好文章,需要你的鼓励


一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

借鉴生态学模型评估AI风险的新方法
本文提出一种评估人工智能风险的新方法,借鉴生态学与演化论视角,从理论生态模型中推导出三项风险指标,涵盖种群模型与生态系统模型。研究旨在为AI治理策略提供量化工具,并对分析局限性及政策改进方向进行了深入探讨,为构建更科学的AI风险评估体系提供参考框架。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。
2018
03/19
12:09
分享
点赞

《网络数据安全管理条例》正式施行,企业数据保护合规如何落地?
AI 时代的隐形身份威胁与安全隐患
中东地区的网络安全记录背后的企业掩盖行为
智慧医疗网络安全发展与创新论坛在南昌成功举办
Veeam CEO谈20亿美元融资、Cohesity-Veritas合并、Rubrik IPO和数据弹性
Veeam公司CEO谈近期20亿美元融资、Cohesity-Veritas并购、Rubrik上市以及数据弹性
Veeam与Palo Alto Networks 集成应对攻击
与生成式AI同行,存储的未来要义
对话亚马逊云科技:如何打造如“应县木塔”般的云韧性
Veeam收购Microsoft 365数据保护初创公司Alcion
